
밑바닥 부터 시작하는 딥러닝 2 -chapter 3 : word2vec
추론 기반 기법
- 미니 배치 학습
- 추론은 말 그대로

주어진 글자에 어떤것이 들어가는지를 추측하는 기법이다.
맥략 -> 모델 -> 단어가 나올 확률분포를 보여주는
모델을 만들자 .

3.1.1 신경망에서 단어 처리
you say goodbye and i say hello
단어중 두단어를 원-핫 표현으로 나타내보자
단어 id 는 -> 으로 가면서 단어 id 를 하나씩 추가해주는것이다.
즉 you 부터 시작했으니 you :0 say:1 goodbye:2 and :3 .. 이런식이다.



w=7 x 3 가 된다. 즉 7개 단어에 은닉충 (w 3)개 전부 연결되었다는 의미
여기서 입력층이 원샷 이기때문에

이렇게 3 개만 사용되고 나머지는 0 이된다.
3.2 CBOW 모델 만들기

위에서 설명했던
you , goodbye 를 입력으로 넣기 때문에 여기서 입력층이 2 개 인것을 알수 있다.
동일한 가중치를 이용해서 h1 , h2 를 output 한뒤 최종 은닉층은 h1+h2 /2 이다 .
(우리가 알고 싶은건 사이에 들어갈 단어이기 때문 )
multiclass 에서는 추정치 를 찾아야되기때문에 softmax 를 이용해서 확률을 구한다.
NOTE
은닉층은 우리가 이해할수 없는 코드로 되어있다. == 인코딩
인코딩을 우리가 이해할수 있는 단어로 변경한다 == 디코딩

위에서 설명한
" 동일한 가중치를 이용해서 h1 , h2 를 output 한뒤 최종 은닉층은 h1+h2 /2 이다 ." 을 그림으로 보여준다.
여기서 w in 은 이해가 되는데 wout 은 뭐냐? 싶을수 도 있다.

위에서 설명한 디코더를 w out 이 한다고 생각한다. 여기서 은닉층은 3개 밖에 안나와서
정확한 확률을 구하기 어렵다. 따라서 wout 를 곱해줘서 출력층이 입력층과 같은 크기가 나오게 만들어야
된다.
이제 multiclass 의 softmax -> cross Entropy error를 하면되는데 여기에서는 두개를 합쳐서 softmax with loss 계층을 만든다.
w (in) 이 단어의 분산에 해당된다.
3.3 학습 데이터 준비
& CBOW 모델 구현하기


이런식으로 바꾼다. 코드는 for 문을 두번스기 때문에 나엿으면 for문 한번에 쓰고 앞뒤로 검색해주는게 더 날거 같아서
코드 해석은 안함
나머지는 책 보면 이해되는 코드
3.5 word2vec 보충
원래는
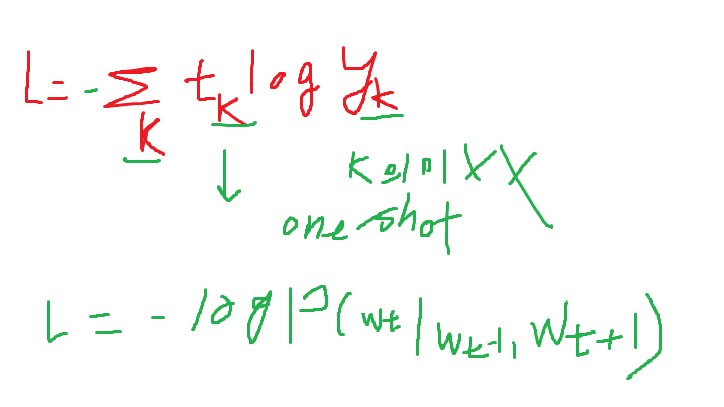

가 되는 것을 볼수 있다.
skip- gram 모델

역으로 생각해보는 문제이다.
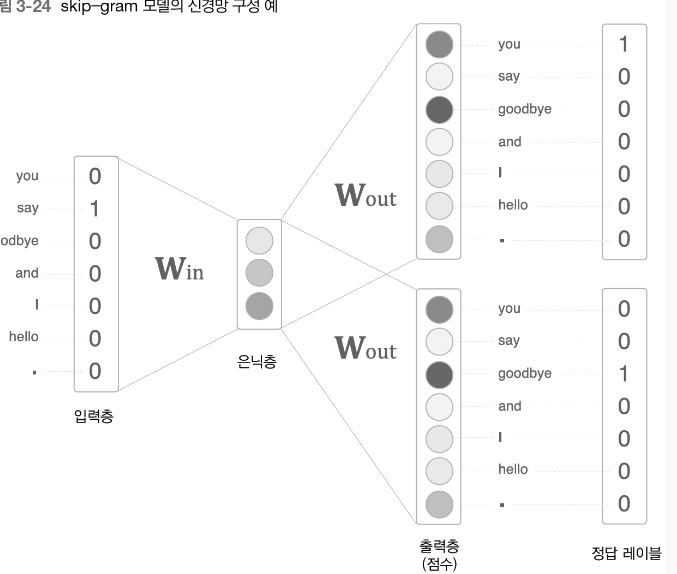
마치 디코더 라고 생각하면 될거 같다.
하나의 입력에 대해서 어떤것이 나올까? 를 모델링한다.
여기서


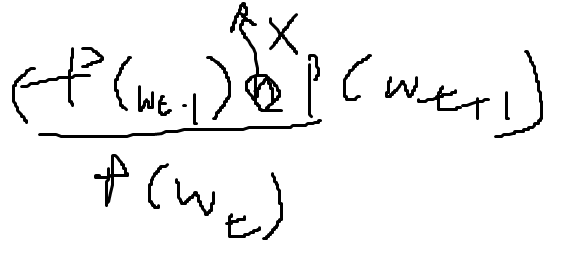
조건부 독립이다. 이것은 서로 독립 ( 연관성이 없다는 것을 놓으면 이렇게 변한다. _



