
Binary cross entropy log loss 해석하기
Understanding binary cross-entropy / log loss: a visual explanation
Have you ever thought about what exactly does it mean to use this loss function?
towardsdatascience.com
이 링크를 번역한거 + 나만의 생각 정리 + 추가함
그전까지 linear 을따라서 하나의 label 만을 구현하였는데 이제부터 다수의 label을 따라서
분류하는 방법에 대해서 서술한다.

label : red, green 이다.
probability of the point being green : 초록색일 확률은 어느 정도인가?
In this setting, green points belong to the positive class (YES, they are green), while red points belong to the negative class (NO, they are not green).
이 셋팅에서 녹색 점은 poistitive class 이고 빨강점은 negative class 이라 가정한다.
우리가 모델을 만든후 초록색일 확률을 구할때 어떻게 그 모델이 예측한 획룰이 좋은지 / 안좋은지
확인할수 있을까? 가 여기서 나오는 binary classificaition 이다.

즉 모델을 형성해서 빨강색인 부분에 있을 확률이 높다는 것은 이 모델이 예측한 모델이 class0 이라는 것이고
초록색 부분에 있으면 예측한 모델이 class 1 이라고 생각한다.
우리는 이중 (binary ) 으로 분류 하기 위해서 sigmoid 함수를 사용하는데

sigmoid 함수를 이용해서 x값이 커질수록 y 값이 커지는 것을 확인할수 있다.

빨강색 점도 sigmoid 함수를 사용해서 x값( 여기서 가로를 x값으로 추정한다) 이 작을수록
y 값이 커진다고 보인다.
여기서 내가 놓친 부분이 이부분이다.
직선을 x축을 상대로 reverse 해서 생각해야되기때문에 ( 수학에서 x리버스 하고 싶으면 y 에 마이너스 붙이면 된다고
초딩때 알려줌_)
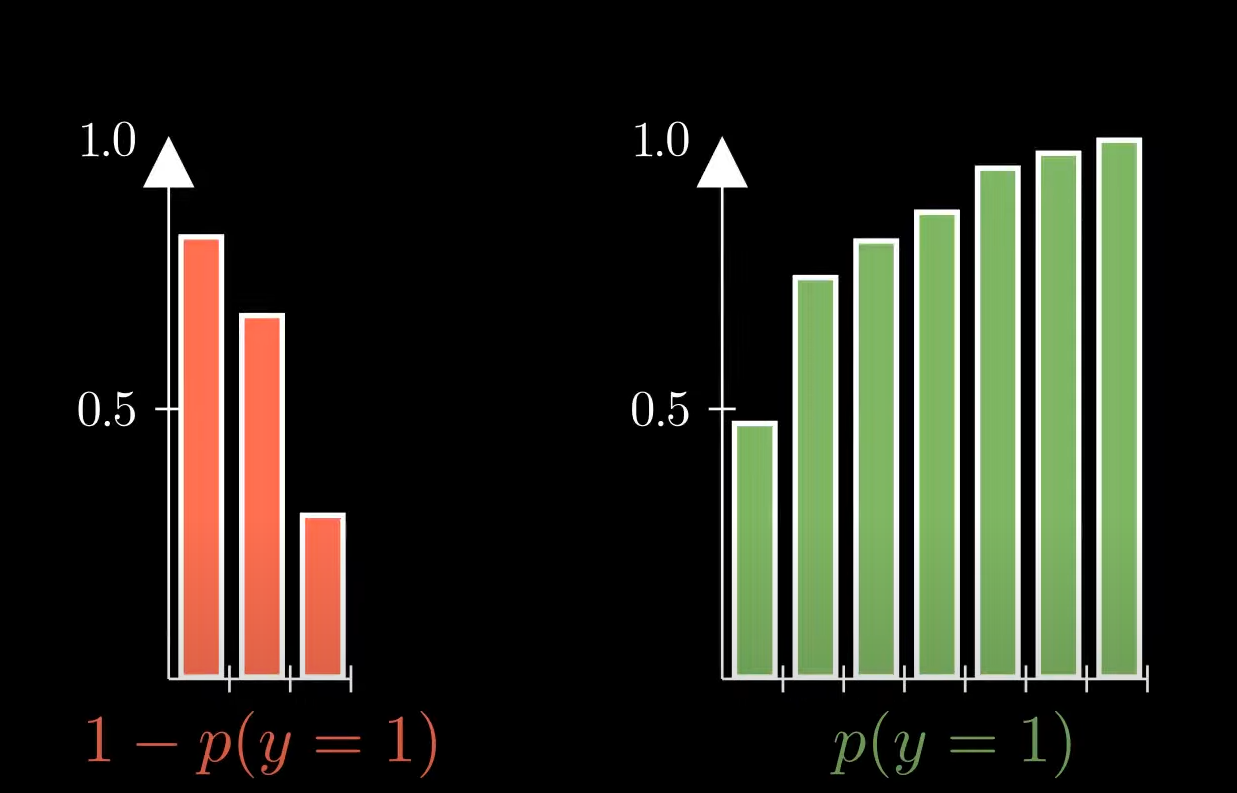
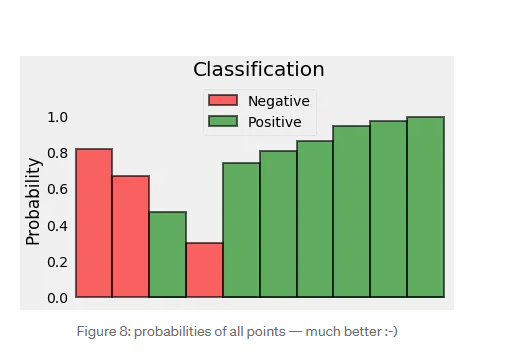
하나로 합치면 이런 모양이 된다.
우리는 이제 loss 를 계산해서 좋은 모델을 형성하고 싶다.

p(x) 는 위에서 본 그래프 하나로 합친거 를 나타낸것이다. 즉 probability 가 크면 loss 가 적다는 의미이고
probability 가 작으면 loss 가 크다고 생각한다.

이제 loss 를 더해서 mean (평균) 을 구하면 그 모델이 얼마나 좋은지 안좋을지 예측할수 있다.
### 부가 설명
Distribution ==q(y)
red는 3 / green 7 인경우의 분포도

Entropy :==
엔트로피는 불 확실성의 측정이다
주어진 distribtuion q(y) 과 관련성이 있다.
. 엔트로피가 작다는것은 항상 옳은 결과값이 나온다는것이고
엔트로피가 크다는 것은 불확실한 결과가 많이 나온다는 것이다.


이식과 이 그래프를 보자
한 클래스의 분표도가 많을수록 에러가 적다는 것을 알수 있다. 즉 이것은
나의 분표도와 에러를 곱한다고 생각하면 편하다

이렇게 생각하면 편하다
true distribution 을 우리가 알고잇다면 ,
true distribution 이 뭔가 뒤져봤더니 걍 전체의 비율에서 각각의 비율을 의미하는거 였다.
우리는 엔트로피를 계산할수 잇다.
만약, 우리가 true distribtion 을 알지 못해서 다른 분포를 통해 true distribution 을 대략적으로 추정해해야된다면
?
Cross-Entropy
원래의 cross entropy는 예측 모형은 실제 분포인 q 를 모르고, 모델링을 하여 q 분포를 예측하고자 하는 것이다. 예측 모델링을 통해 구한 분포를 p(x) 라고 해보자. 실제 분포인 q를 예측하는 p 분포를 만들었을 때, 이 때 cross-entropy 는 아래와 같이 정의된다.
실제 분포 =q(x)
예측 분포 =p(x)
예측분포 * 실제분포의 오류도를 곱해서 불확실성을 알아보는거라고 생각


Kullback-Leibler Divergence
dissimilarity between two distributions: 두가지 분포 사이에서 얼마나 다른가를 측정하는것
cross entropy -entropy
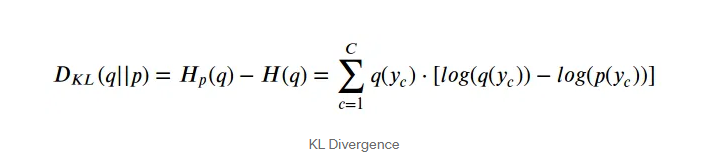

보니까 위의 식을 그 수학적으로 앞으로 빼고 뒤로 조정한거라는 것을 알수 있다.
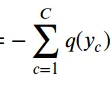
이 친구를 앞으로 빼고 수학적으로 한거라는 의미 즉이 수가 작다는 것은 실제랑 예측이랑 비슷하다는 것이고
이 값이 크다는 의미는 실제랑 예측이랑 다르다는 의미이다.
Loss Function
N-points 을 이용해서 train 셋트를 만들어 cross entropy loss 를 구한다.
우리는 효율적으로 p(y) 를 훈련한다.
여기서 우리는 q(y) 실제의 값을 안다.
각각의 point 의 확률은 1/n 이기 때문에

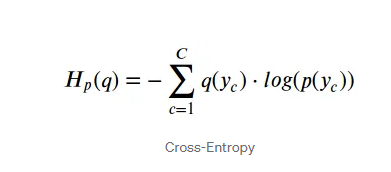

링크에 있는 동영상 을 보면 이해가 된다.



