
만들면서 배우는 파이토치 딥러닝 02
# DataLoader 구현
1. imagesets/main/train.txt

파일을 까보니 이런식으로 이름이 있음
train_id_names
val_id_names
2. for line in open ( 저 파일)
osp.join(~'$s.jpg') % 2008_00002
이 %s에 대해서 찾아봣느데 별거 아니고 그냥 + 형식이라고 생각하면된다고함

이런식으로 train_img_list= list() 에 담겨있다
train_(img / anno) _list
val_ (img/anno)_list
으로 구성되어있다
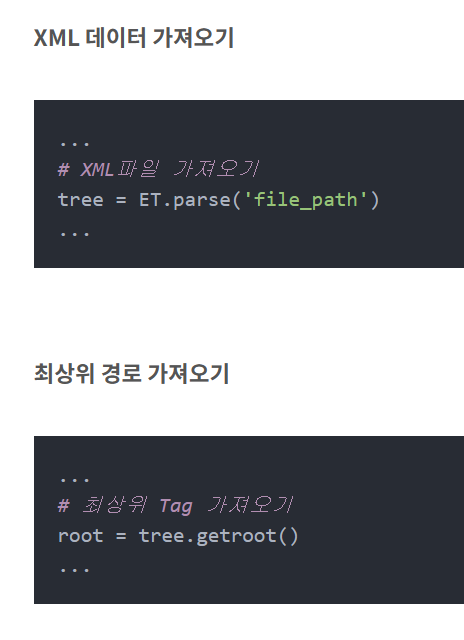
# 2.2.4 xml 형식의 어노테이션 데이터를 리스트로 변환하기
# __call__ 함수
python 의 call 함수는 매번 날..힘들게 한다..

1. transform_anno = Anno_xml2list( 배열함수 ) 이것은

class 를 선언한거니 __init__ 에 자동으로 가게 되서
self.classes= [ .....] 가 되는거고
2. transform_anno( val_anno_list[ind] , width, heigth) 이거는
__call__ 을 선언하게 된다.
085 XML에서 엘리먼트와 콘텐츠를 읽으려면? ― xml.etree.ElementTree - 점프 투 파이썬 - 라이브러리 예제 편 (wikidocs.net)
085 XML에서 엘리먼트와 콘텐츠를 읽으려면? ― xml.etree.ElementTree
xml.etree.ElementTree는 XML 문서를 파싱(parsing)하고 검색할 때 사용하는 모듈이다. > xml.etree.ElementTree 모듈은 XML 문서를 …
wikidocs.net
ElementTree를 활용하여 xml 파싱하기 :: 대학원생이 쉽게 설명해보기 (tistory.com)
ElementTree를 활용하여 xml 파싱하기
파싱할 xml은 다음과 같습니다. ml_string = ''' 1 good 1 nice 2 research 3 well ''' ElementTree를 통해 xml 파일을 지정하고 root에 접근하는 방법은 다음과 같습니다. tree = elemTree.parse('ml.xml') root = tree.getroot() * 여
hwiyong.tistory.com
3. xml 파싱하기
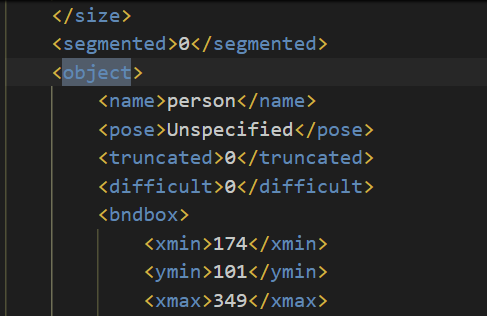
for obj in xml.iter('object')
> obj 갯수만큼 실행하자 / object 안에 iter 하자 ..
한줄한줄 이름을 obj 으로 설정
bbox= obj.find('bndbox')
bbox.find(pt) 으로 cur_pixel

데이터를 뽑는 과정은 이해 했다. 근데 왜
# cur_pixel /= width ( 데이터의 실제 크기 )
앞에 책에서
SSD 관련 용어들
ssd의 전체적인 구조를 살펴보자
velog.io
# 2.2.6
DataTransform ()함수
plt.imshow( cv2.cvtColor( img, cv2.color_bgr2rgb)
지금 opencv 에서 그림을 불러오면 RGB 가 아닌 BGR 이기때문에 이것을 다시 변경해야 원본
이미지를 확인할수 있다고 한다.

이런식으로 그림의 색이 반전되는 함수이다.
# transform= DataTransform(input_Size, color_mean)
으로 데이터 인스턴스를 선언하니까 이때는 __init__ 만 보면 된다.
resize( input_size) > 데이터를 input x input_size 으로변경
substractMean( color_mean) > BGR 색상의 평균값 빼기
# img_transformed, boxes, labels= transform( img,phase,anno_list[: ,:4~
여기서 anno_list
boxs=anno_list[:, :4] 는 > xmin, ymin, xmax, ymax 의 결과
lable=anno_list[: ,4] > label 의 번호
self.data_transform[phas] (img, boxs, labels) <-
img 만 transform 하는게 아니라 우리가 구해놨던 것들도다 transform 하라고 하신다..
# 2.2.7 데이터 셋 작성
train_dataset= V0cDataset( train_img_list ( 위에 이미지 링크가 .jpg 가 담겨있는 배열 , )
train_anno_list( xml 담겨있는 배열), transform= () [이미지 변경시키는거] , transform= Annoxml2List( class)) [xmin, xmax, ymin,ymax, label] 나오는거
VocDataset 코드 분석
// 이런.. github 에서 파일을 못받았다.. 헷갈리는거만작성
1) image_file_path= self.lmg_list[index] <- index 받아서 하나의 이미지만 뽑아온다.
2) img= cv2.imread( 이미지 path) [높이][폭][bgr] -> height, width,cannel = img
3) anno_file_path= 위와 비슷
4) anno_list= self.transform_anno( anno_file_path [ 1개] , width, heigth) 으로 --> [..xmax, ymin,ymax, label]
5) 이미지/ phase( train/ val ) / anno_list [..xmax, ymin,ymax, / label 를 transform 으로 전처리함
Transform 하는 부분 으로 이미지 , xmal... label 을 변형시킨다.
6) 이미지 bgr -> rgb으로 변경 / 색상채널. 높이, 폭 으로 변경

7) box 와 label 은 다시 한줄로 묶는다 .
np.hstack

np.hstack( boxes , np.expand_dims(lables, axis=1) == > [label] 이런식으로 된다. )
따라서 [0.09 , 0.003, 0.01.0.009, 19] 이런형태가 여러개인 가만들어지는것을 볼수 잇다.
즉 train_set. __getitem__ 은 => 이미지 transform 한거 / box transform +label 을 뽑을수있다
!!!! 매번 그럼 train_Set 에있는 이미지 각각을 어떻게 뽑을것인가 ..? 고민하는데 여기서는 __get__item ( index) 가되어있어 데이터출력시 train_Set.__getitem__ ( index) 를 넣어주면 뽑아주는것을 볼수 있다.
#2.3 데이터 로더 구현
- 이미지
- 이미지 마다 꺼낼 어노테이션 정보(네모 이름 , 네모 크기,,)
-gt 변수의 크기가 다름
여기서 target 은 네모의정보이다!
def od_collate_fn
1강에서도봤었지만 데이터 로더의 return 값은
return imgs, targets 이다.
def od_collate_fn(batch):
"""
Dataset에서 꺼내는 어노테이션 데이터의 크기는 화상마다 다르다.
화상 내의 물체 수가 두개이면 (2, 5)사이즈이지만, 세 개이면 (3, 5) 등으로 바뀐다.
변화에 대응하는 DataLoader를 만드는 collate_fn을 작성한다.
collate_fn은 파이토치 리스트로 mini batch를 작성하는 함수이디ㅏ.
미니 배치 분량 화상이 나열된 리스트 변수 batch에 미니 배치 번호를 지정하는
차원을 가장 앞에 하나 추가하여 리스트 형태를 변형한다.
"""
targets = []
imgs = []
for sample in batch:
imgs.append(sample[0]) # sample[0]은 화상 gt
targets.append(torch.FloatTensor(sample[1])) # sample[1]은 어노테이션 gt
# imgs는 미니배치 크기으 ㅣ리스트
# 리스트 요소는 torch.Size([3, 300, 300])
# 이 리스트를 torch.Size([batch_num, 3, 300, 300])의 텐서로 변환
imgs = torch.stack(imgs, dim=0)
# targets은 어노테이션의 정답인 gt 리스트
# 리스트 크기 = 미니 배치 크기
# targets 리스트의 요소는 [n, 5]
# n은 화상마다 다르며 화상 속 물체의 수
# 5는 [xmin, ymin, xmax, ymax, class_index]
return imgs, targets
여기서 def_collate_fn ( batch) <- 이 batch 는 train_dataset에서 batch 크기 만큼 뜯은거라고 생각하면 된다.
imgs[] 에다가 img = torch.from_numpy 으로 변형된것을 넣고 <- rgb 값으로 된
target[[] 에다가 우리가 만들었던 [xmin, ymin, xmax, ymax, class_index] 을 넣는다.

여기서 급 # 이 리스트를 torch.size([batch_num,3,300,300] 텐서로변환한다. 하는데
img= torch.stack( imgs, batch_num ,dim=0) 이 아닌가 싶다;; 머용
# 데이터 로더 작성
batch_size = 4
train_dataloader = data.DataLoader(
train_dataset,
batch_size =batch_size, shuffle=True,
collate_fn=od_collate_fn)
val_dataloader = data.DataLoader(
val_dataset,
batch_size =batch_size, shuffle=True,
collate_fn=od_collate_fn)
# 사전형 변수에 정리
dataloaders_dict = {'train' : train_dataloader,
'val' : val_dataloader}
# 동작 확인
batch_iterator = iter(dataloaders_dict['val']) # 반복자로 변환
images, targets = next(batch_iterator) # 첫번째 요소 추출
print(images.size()) # torch.Size([4, 3, 300, 300])
print(len(targets))
print(targets[1].size()) #
data. DataLoader 에서 collate_fn= collate_fn 을 불러온다.

이미지의 크기 가 다르니까 우리는 collate_fn 을 선언해야된다.
# 2,4 본격적인 네트워크 모델을 구현하자
- vgg : 1 soure1 2 source2
source2 -> extras
source 마다 크기가 다르다.
ex) 38 x 38 = source1 <- 1440 의 특징이 있다. 1x1= source6 <- 1 나의특징이 있다.
source1은 작은 물체를 감지한다./ but 합성곱 처리 횟수가 적기 때문에 감지가 미숙하다.


offset 이란 위의 설명과 같이 offset 을더해 신경망이 넓게 퍼지는 특성을 가지게한다.
다시한번 개념을 상기 시킬 시간
입력은 이미지
출력은
- 이미지 안에 물체가 존재하는지 나타내는 바운딩 박스의 위치와 크기 정보
- 바운딩 박스가 어떤 물체인지 나타내는라벨
- 검색 신뢰도 == confidnece
# loc 이란?
source1 ~ 6 까지 box 의크기를 구했다.
38x38 , 19x19 , 10x10 , 5x5 , 3x3 , 1x1
= 1940 개이다.
그러나 화면비가 다른 Dbox 도 구하고싶다.
4개의 Dbox 을 사용한다.
bbox_aspect_num[4,6,6,6,4,4]
38X38x4 + ....
1. 작은 정사각형 2, 큰정사각형, 3, 세로로 긴 직사각형 4. 가로로 긴 직사각형

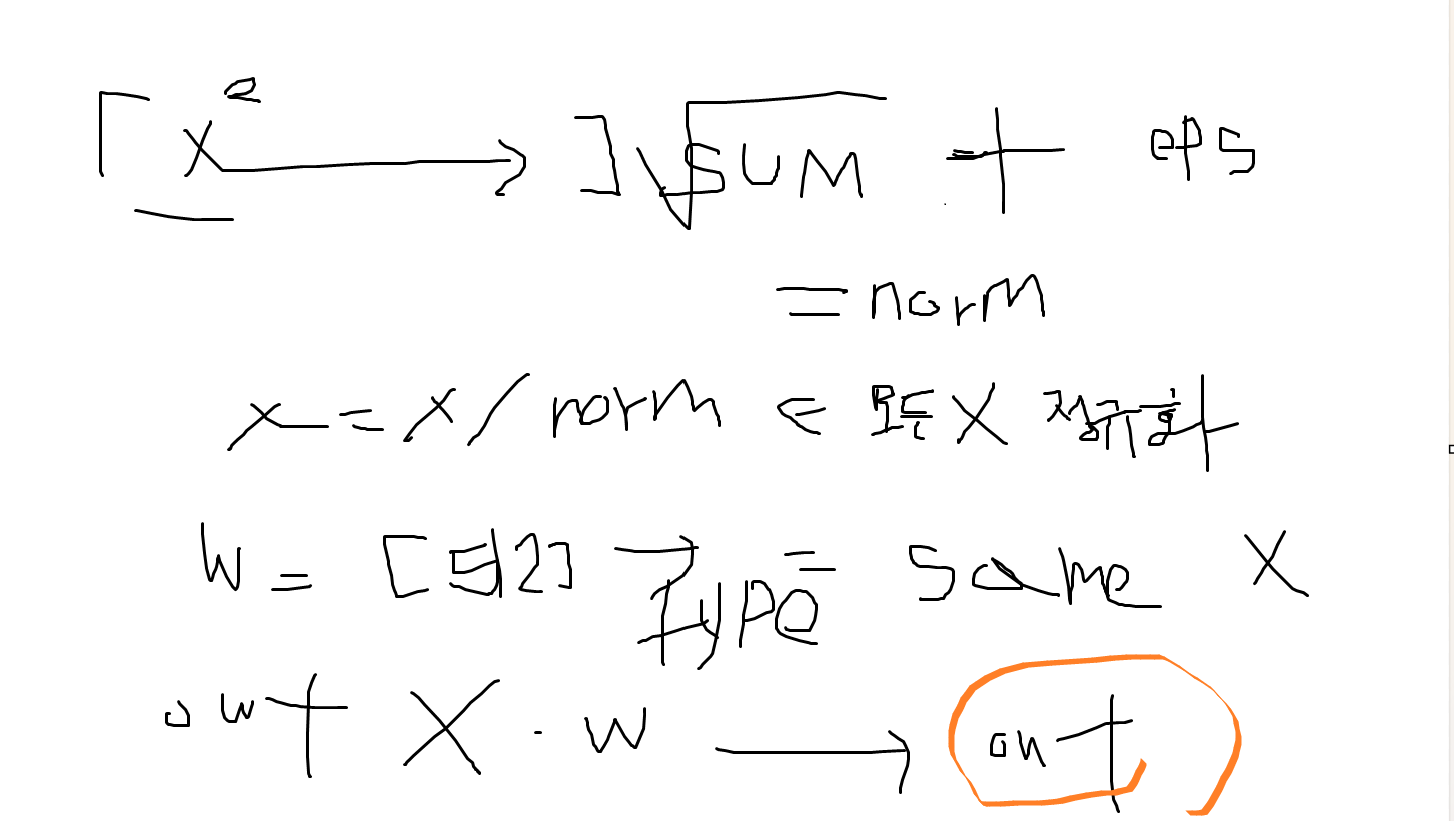
# L2norm
채널마나사이즈가 다른 문제점이 있어 정규화 하는데 어려움이 발생



self.weight= nn.parameter(torch.Tensor( 512))
[512] 인것을
weight= self.weight.unsqueeze(0) . unsqueeze(2).unsequeeze(3).expand_as(x)
<- [ batch_num, 512,

# 2.4.6 디포트 박스 구현
>>> for i, letter in enumerate(['A', 'B', 'C']):
... print(i, letter)
...
0 A
1 B
2 C
for i ,j in product( range(38 == 1~38까지의수 ) repeat=2 (2개만 뽑아봐라 )


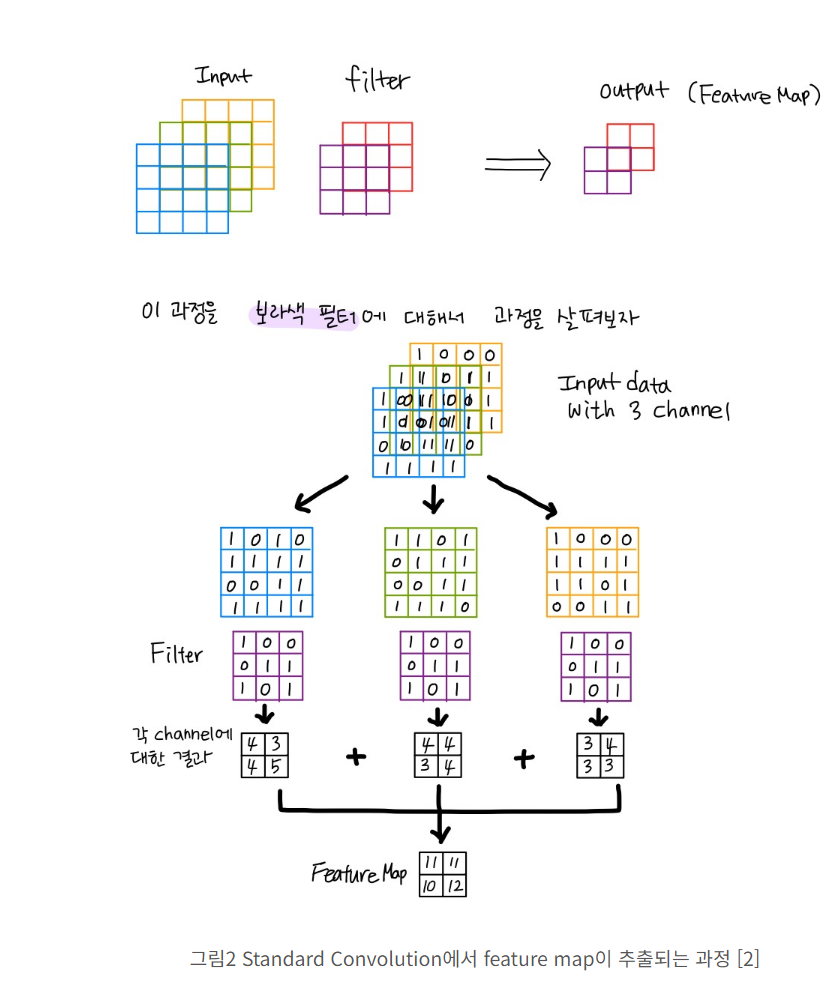


필터는 각각의 rgb 와 곱을 한다음 + 을 해서 결국 하나의 필터는 --> 3개의 max + sum 으로 작용된다고 생각하면된다.
여기서는 2d 연산으로 나타냈는데

이런식으로 필터도 3차원으로 생각해서 max + sum 해주면 이해가 된다.

#Non- Maximum supression
!!! 잘 설명된 영상이 있다.
SSD 논문(SSD: Single Shot MultiBox Detector) 리뷰 (tistory.com)
SSD 논문(SSD: Single Shot MultiBox Detector) 리뷰
이번 포스팅에서는 SSD 논문(SSD: Single Shot MultiBox Detector)을 읽고 정리해봤습니다. RCNN 계열의 2-stage detector는 region proposals와 같은 다양한 view를 모델에 제공하여 높은 정확도를 보여주고 있습니다.
herbwood.tistory.com



