
밑바닥 부터 시작하는 딥러닝 6 장
6.1 RNN 의 문제점
> 기울기손실 / 기울기폭팔이 일어나서 장기 의존 관계를 학습하기 어렵다,
기울기 손실 / 기울기 폭팔
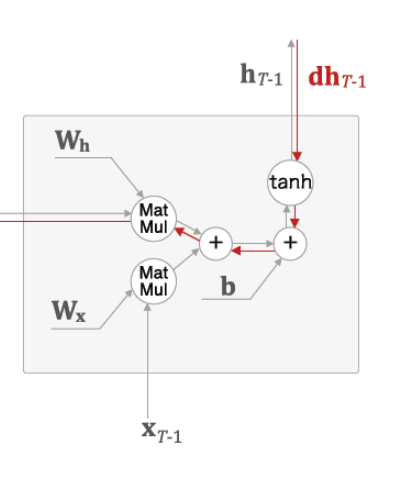
dh 은 tanh -> + -> matMul 식으로 이동한다.
1) tanh 의 문제점

tanh 을 미분해보면 x가 -2 와 2 사이에만 1 으로 셋팅되며 다른 부분은 0 으로 되는것을 볼수 있다. 따라서 기울기가 점점 작아지는 영향이 생긴다. 우리는 time rnn 을 사용하므로 ( rnn 은 제귀다 ) > tanh 함수가 T번 사용되면 작아지는 영향도 T번 반복되서 최종적으로 0 에 가깝게 수렴 할수도 있다.
2) Matmul 의 문제점

똑같은 가중치 wh ^T 가 반복되는데
wh 의 값이 크면
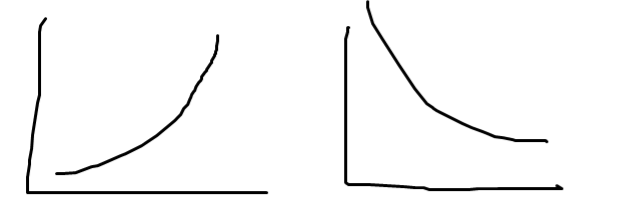
가 되는 결과가 생긴다.
6.1.4 기울기 폭팔대책
--> 기울기 클리핑이라는 기법을 사용한다.
if 기울기 >= 문턱 :
기울기 = 문턱 / 기울기 ( 크기 )
으로 기울기를 다시 셋팅한다.

rate<1 ==> 분모가 커지면 즉 기울기가 커지는경우 기울기를 rate를 곱해준다는 뜻이다.
기울기를 작게 만들어준다는 의미 이다.
6.2 기울기 소실과 LSTM
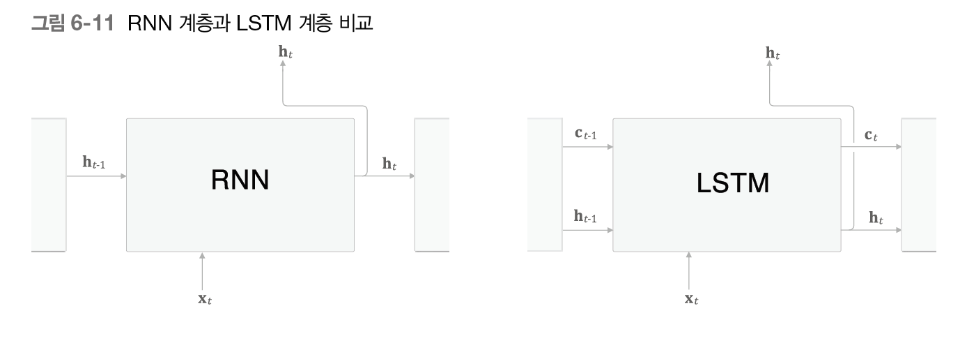
RNN 에 경로 c를 추가한다.
c = 기억셀이라한다.
- 데이터를 자기 자신으로 주고 받는 특징이다.
- 다른 계층으로는 출력하지 않는다.
- 과거로부터 t까지에 필요한 정보가 저장되어있다.
c (기억셀) 을 바탕으로 은닉상태 ht를출력한다.

ct 는 = ct-1 , ht-1 , xt 에 어떤 계산을 통해서 ct를 생성해나간다. 그후 tanh(ct) = ht 를 생성한다.
## 게이트란?
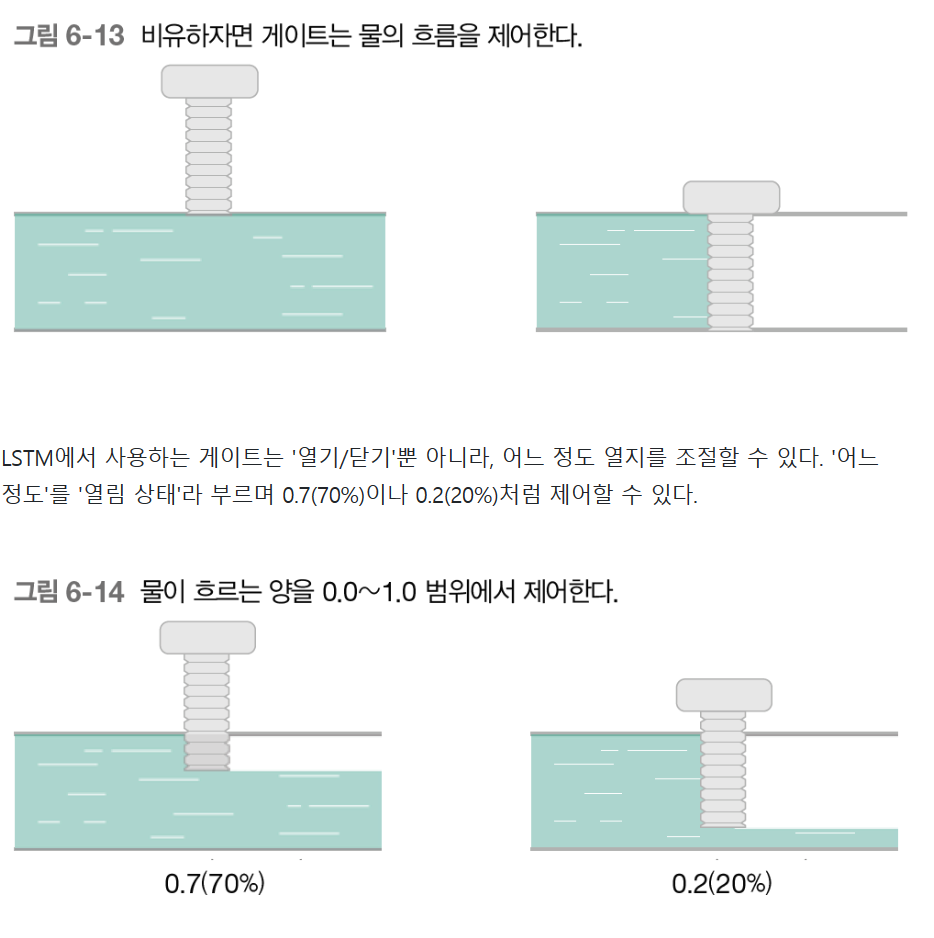
물을 몇퍼센트로 보낼것인가? 라고 생각한다. 마치 담 처럼 생각한다.
퍼센트는 0-1 사이로 나타낼수 있다.
즉 70 프로는 사실상 0.7 이다. 이렇게 나타낼수 있게 하기 위해 시그모이드 함수를 사용해서 변형시킨다.
6.2.3 output 게이트
tanh(ct) 에 얼마나 그것이 중요한지 를 판단하는 함수를 추가해준다.
이것을 output 게이트 ( 출력 게이트) 라고 부른다.

아까 시그모이드 함수의 이용법에 대해서 서술하였다.
같은 의미로 시그모이드 함수를 사용해서 o 를 구한다.
이 o 를 tanh(Ct) 에다가 곱해준다.
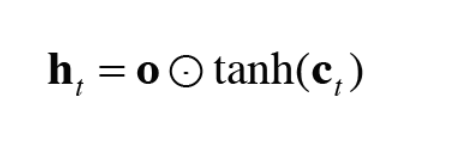
아다마로 곱 이 (0) 이중 동그라미 인데 이것은 같은 위치에 있는것들을 곱해주는 쉬운 공식이다.
6.2.3 forget 게이트
fotget 은 말그대로 얼마나 잊을것인가 ?이다. 앞에서 니체가 망각은 더 나은 전진을 낳는다라고 쓴 글이 있는데 이것을 위해서 쓴거 같다.

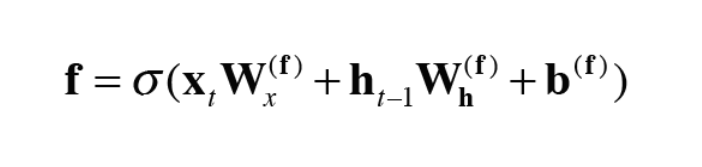
식은 동일하다.
이것을 c t-1 에다가 곱해준다.
6.2.5 새로 기억되는 셀
새로 기억되는 게이트는 tanh 노드를 사용한다..
정보가 추가되기 때문이다. 여기서는 게이트가 아닌 정보 추가! 이다. 따라서 시그모이드 함수를 사용하지 않는다.


6.2.5 새로 기억되는 게이트 의 가치는 얼마정도인가?

6.2.5 LSTM 의 기울기의 흐름

matmul 은 계산이 누적된다는 것을 알수 있다. 즉 내적을 사용했으니
다른 차원의 수를 그 차원에 존재하는 것과 곱햇으니 . 값이 누적되면서 바뀐다. 하지만
LTSM 은 matmul() 함수를 사용하는 대신에 아마다르 곱을 해서 곱셈의 효과가 누적되지 않는다.


즉 이런식으로 된다는 것을 알수 있다.
우리는 같은 공식을 여러번 사용하였다. 이것을 변환해서 처음에 다 계산해놓은 다음
slice 노드를 통해 결과를 꺼내주는 단순한 노드로 변환시킨다.
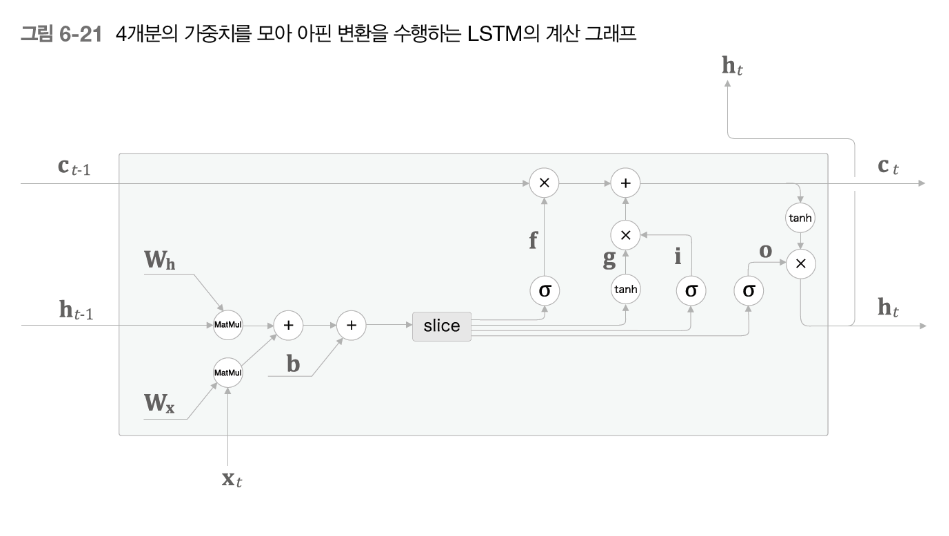
순전파는 딱히 설명하지 않겠다.
역전파
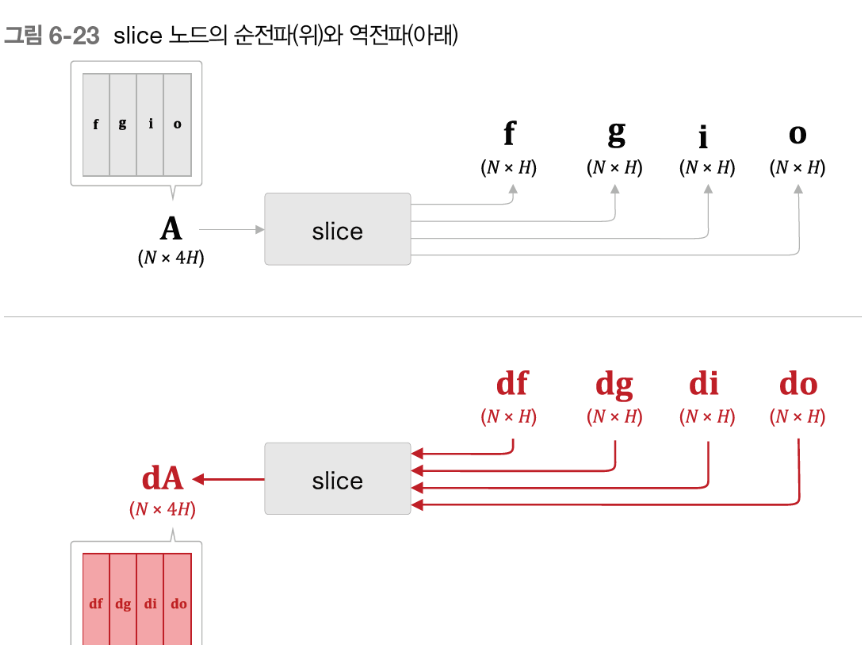
역전파는 반대로 4개의 기울기를 결합해야된다.
이렇게 가로로 연결하기 위해서 우리는 np.hstack () 을 사용한다.
6.3.1 Time LSTM 구현하기
5장에서 설명했던 코드와 딱히 다를게 없다.
layer= LSTM(*self.param) 으로 변한거 뿐이다.
6.3.1 LSTM 계층 다층화

LTSM 계층을 1층 ... 3층 이런식으로 여러 겁 쌓아서 모델의 정확도를 향상시킨다.
6.5.2. 드롭 아웃에 의한 과적합 억제
층을 깊게 쌓으면 표현력이 풍부한 모델을 만들수도 있지만 과적합을 만든다
과접합 == overfit ( 모델을 예측하기 위해서 만든게 아닌 트레이닝한거만 맞게 모델링이 된거 )
따라서 이런 괴적합을 억제 하기 위해서 모델의 복잡도를 줄여야되는데 여기서는 드롭아웃을 사용해서 설명한다.

여기서는 시계열 방향( 시간축 방향으로 ) dropout 을 넣는 대신에 깊이 방향으로 droupout 을 넣어서 과적합을 방지한다.

번형 드롭아웃이다.
이전과 달리 시간 방향으로 dropout 을 넣는다. 이때 같은 계층에 속한 dropout 은 같은 마스크를 공유한다.
이렇게 마스크가 고정되면 정보가 지수적으로 손실되는 상태를 피할수 있다.
6.3.3 가중치 공유
가중치를 공유해서 얻는 이점 : 학습해야될 매개변수 수를 줄일수 있으며 그 결과 학습이 쉬워진다.
또한 매개변수가 줄어들기 때문에 과적합이 억제 되는것을 막을 수 있다.



