
밑바닥 부터 시작하는 딥러닝 2 -chapter 4 : word2vec 속도개선
1 .word2vec 개선
두 계산이 병목되는 문제점 (병목이란? 속도 차이가 달라서 중간에 데이터가 쌓이는 문제점을 말한다 . )
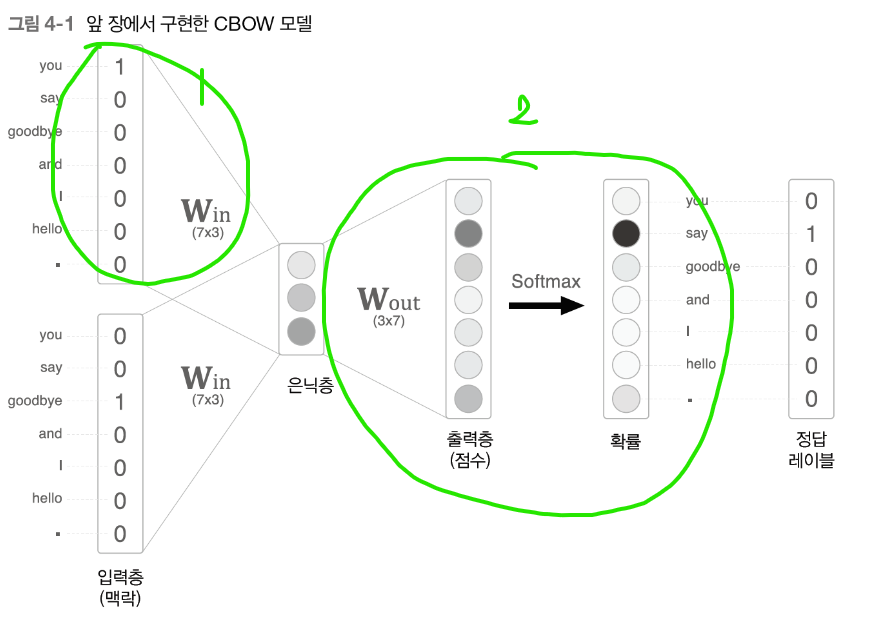
1-1 입력층의 원핫 표현 / 가중치의 행렬 win 의 곱
1-2 은닉층의 가중치 행렬 w out 의 곱 및 softmax 계산
1-1 원핫 표현 시간 多 -> 벡터의 크기 多
벡터의 크기 ?( 내 생각에는 벡터는 하나의 방향을 나타내는 거라고 생각하면 된다. 즉 여러개의 방향이 쌓이면 차원이 되는데 여기서는 하나만 1 이고 나머지는 0 이가 때문에 차원은 그렇게 크지는 않으나. 벡터의 크기는 크다는 것을 알수 있다. )
어쨌든 100만 단어 일시 원소수가 100만개 이기 때문에 벡터의 크기는 크다고 말할수있다.
1-2 wout / softamx 오래걸림
4.1 EmBedding 계층
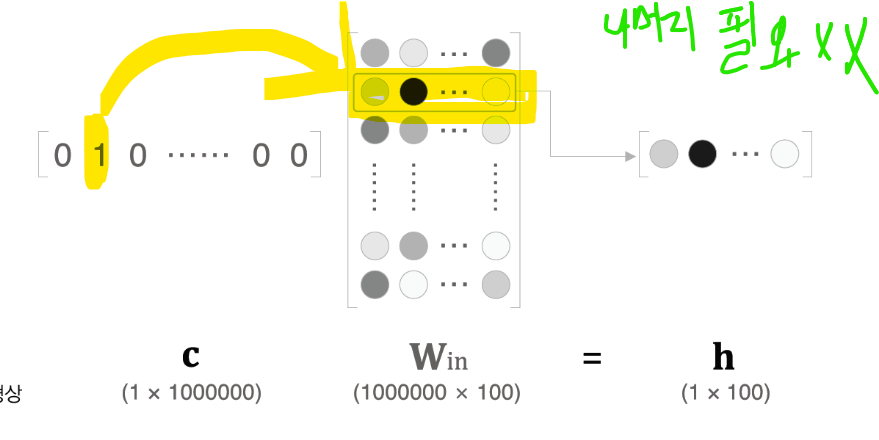
forward는 win 에서 자기 자신에 해당하는 배열만 추출해서 흘러 보낸다.
따라서 역전파에서는 그대로 흘러주기만 하면된다.
backforward

에서 dw 와 dh 가 이해가 안갔다. (그래서 밑 바닥 부터 시작하는 1 책 다시봄)
dh 는 자기 자신이니까 변한게 없으니 자신의 원래 상태 인것 이였고 (틀릴수도 잇음
dw은 뭐지???? 싶었다. 편미분인게 분명한데 어떤 상태에서 편미분인지 분모가 안적혀있어서 헷갈렷다.
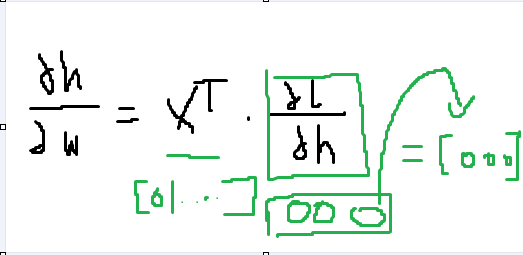
그래서 결국은 이런상태인거 같다.
### 왜 softmax+ cross Entropy Error 의 backward 는 y1-t1 인가?
처음 봣을때는 이해가 안됫는데 계속보다보니가 알겠다.
https://questionet.tistory.com/23
여기에 설명 잘되어있음

이부분에서 사실 이해안되서 많이 찾아봤는데

라고 생각했다. 그래서 이게 뭔가 고민해봤는데 우리가 중요한거는 미분이지 그 값이 아니다.
그니까 결국은

y= exp(x) 식을 가상으로 있다고 생각하고 미분 한다고 생각해야되는거 같다 (아닐수도 ^^:;
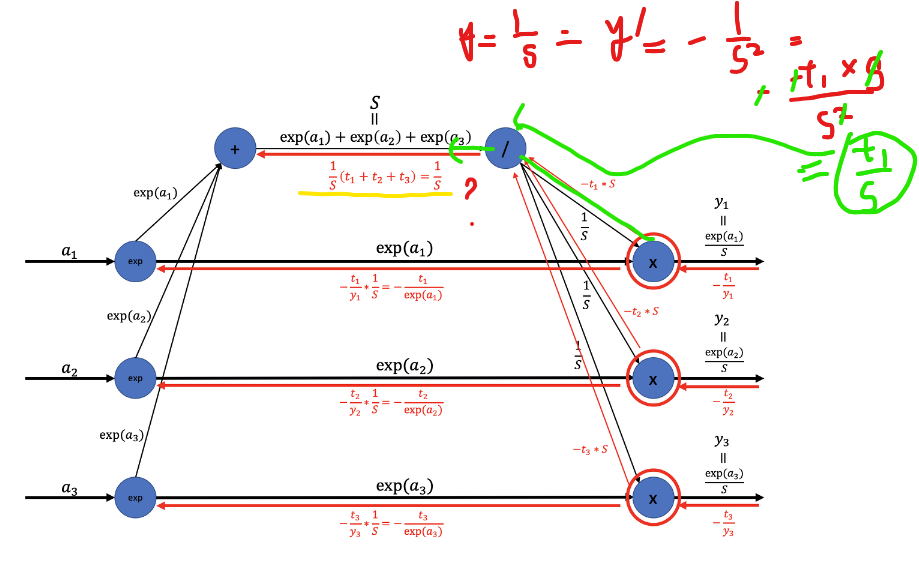
이부분도 이해가 안됬는데 이런식으로 하면 이해가 된다.
(어쨋뜬.. 책은 다 ... 하나도 안써있고 알아서 생각해라 인데 가끔 블로그 보면 이해 안될때도 많다.. 근데 이게 맞는 해석인지는 나도 모르겠음....)

어쨌든 이런식으로 쉽게 나타나면 (yt-t , y2-t2 ,y3-t3) 가 나오게된다.
### 다시 본문

2개의 값이 dw에 할당하는데 중복이 생긴다 이때는 더하기를 해야되는데 책에서는
(왜 더해야 하는지는 각자 생각해봅시다라고 적혀져 있다,)
3장에서 우리는 h= 1/2(h1+h2) 을 해주었다.
4.2 word2vec 개선
1-2 은닉층의 가중치 행렬 w out 의 곱 및 softmax 계산 에 대해서 서술한다.
4.2.2 다중 분류에서 이진분류로
다중분류 (여러개중에서 이거 맞나요? ) -> 이중분류 ( 이것은 __이거 인가요 ? yes / no)
으로 변한해 보자
"you " __ " goodbye" -> 타킷 단어가 무엇인가요 ? ( 여러가지 확률을 보여줌)
이것을 이진분류 -> yes / no 으로 답할수 있는가 으로 변환하겠다.
"you " __ " goodbye" -> " say" 입니까? yes/ no

처음에 시작할때 백만개의 단어를 원핫 샷 으로 했고 w in 가중치를 통해 h 가 1*100 으로 줄어들었다.
그 h 를다시 wout 을해서 백만개의 단어중 각각 나올 확률을알아보는거였다.
하지만 여기서는 개선을 위해서 wout 을 전체를 곱하는게 아닌 say 의 wout만 나올 확률을 물어보는 듯하다.
4.2.3 교차 엔트로피 오차
이전 블로그에서 교차 엔트로피 loss 는 이런식으로 진행된다고 서술하였다.
즉 실제의 엔트로피와 내가 예상한 엔트로피 오차 간의 차이가 얼마나 나는지 를 알아보는 공식이다.
저번 블로그에서 적은 식을 이용해서 변경하면

이렇게 나온다.
Softmax와 Cross entropy
학습시키는 데이터의 Feature가 3가지이고 이 데이터들을 총 3개의 분류로 나눈다고 해봅시다. 이때 우리는 하나의 feature에 대하여 총 3가지로 분류해줄 weight값이 필요합니다. 만약 데이터의 Feature
selfish-developer.com
와
여기 참조
Understanding binary cross-entropy / log loss: a visual explanation
Have you ever thought about what exactly does it mean to use this loss function?
towardsdatascience.com
좀 이해 안되서 다시 공부하고 쓸예정



